Machine Learning: How to Prevent Overfitting
Introduction:
When building a machine learning model, it is important to make sure that your model is not over-fitting or under-fitting. While under-fitting is usually the result of a model not having enough data, over-fitting can be the result of a range of different scenarios. The objective in machine learning is to build a model that performs well with both the training data and the new data that is added to make predictions.
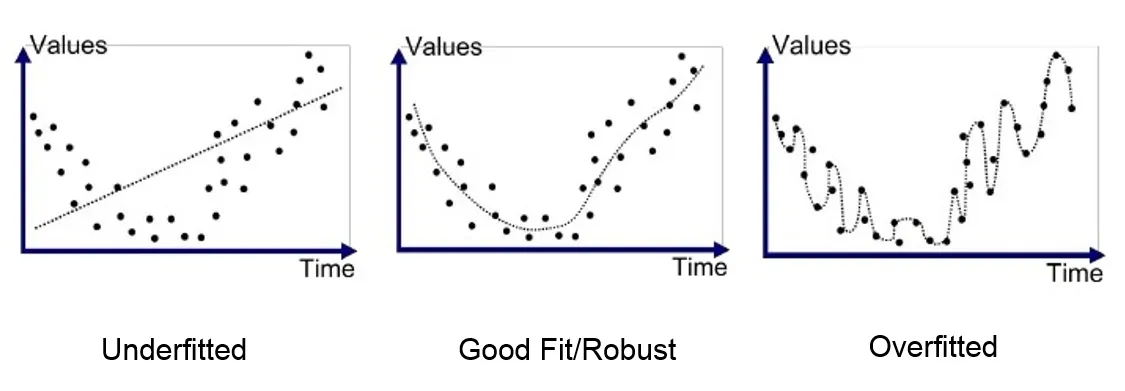
- Under-fitting — when a statistical model does not adequately capture the underlying structure of the data and, therefore, does not include some parameters that would appear in a correctly specified model.
- Over-fitting — when a statistical model contains more parameters that can be justified by the data and includes the residual variation (“noise”) as if the variation represents underlying model structure. The model does not generalize well from the training data to new, unseen data.
- Good fit — when a statistical model adequately learns the training dataset and generalizes well to new data
Bias-Variance Tradeoff:
In order to understand over-fitting better, we should look at the problems that cause under-fitting. Under-fitting occurs when a model is too simple (not enough observations or features), and therefore, does not learn well from the data that it is given. These models have less variance in their predictions, but more bias towards certain outcomes. On the other hand, models that are too complex have more variance in their predictions. Typically, we can reduce error from bias but might increase error from variance as a result, or vice versa. This is known as the bias-variance tradeoff.

How to Tell if Model is Over-fitting:
With machine learning, it is difficult to determine how well a model will perform on new data until it is actually tested. To avoid this issue, it is important to split the data that is used to train the model into training and testing data. As a general rule of thumb, the training data and testing data should have a split anywhere between 80% training data and 20% testing data to 70% training data and 30% testing data.

Once the training data and testing data is split, you can determine whether your model is over-fitting by comparing how the model performs on the training set to how it performs on the testing set. If the model does significantly better on the training set than on the testing set, than it is likely over-fitting.
Ways to Prevent Over-fitting:

- Train with more Data — training with more data can help the model determine trends in the data in order to make more accurate predictions. Although this can be an effective way to prevent over-fitting, it is important that the data is clean and relevant (no “noisy” data) or else this technique may not be beneficial.
- Cross-Validation — used to estimate how accurately a predictive model will perform in practice. Cross-validation involves partitioning a sample of data into subsets, performing analysis on the training set and validating analysis on the testing set. The goal of cross-validation is to test a model’s ability to predict new data that was not used in estimating it, in order to flag whether over-fitting will be a problem for the model.
- Early Stopping — If you’re training a model iteratively, you can determine how well each iteration on the model performs. New iterations will often help improve a model up to a certain iteration. After that certain iteration, the model’s accuracy may decline and begin to overfit to the training data.
- Regularization — This is a form of regression that constrains the coefficient estimates of the model towards zero. This technique discourages a more complex model to avoid the risk of over-fitting. Two common forms of regularization are Ridge Regression and Lasso Regression. While Ridge Regression shrinks the coefficients for less important predictors to close to zero, Lasso Regression will shrink the coefficients for less important predictors to zero, essentially performing variable selection.
- Ensembling — Ensemble methods are techniques that create multiple models and then combine them to produce improved results. These methods will usually produce more accurate solutions than a single model would. One common ensemble method is the voting classifier. With hard voting, the prediction class that received the highest number of votes from each individual model will be chosen. With soft voting, the total number of votes from each individual model is summed up in order to choose the prediction class.
References:
- Brownlee, Jason. “How to Avoid Overfitting in Deep Learning Neural Networks.” Machine Learning Mastery, 6 Aug. 2019, machinelearningmastery.com/introduction-to-regularization-to-reduce-overfitting-and-improve-generalization-error/.
- Lin, Chuan-en (David). “8 Simple Techniques to Prevent Overfitting.” Medium, Towards Data Science, 7 June 2020, towardsdatascience.com/8-simple-techniques-to-prevent-overfitting-4d443da2ef7d.
- “Overfitting in Machine Learning: What It Is and How to Prevent It.” EliteDataScience, 23 May 2020, elitedatascience.com/overfitting-in-machine-learning.
- Necati Demir, PhD. “Ensemble Methods: Elegant Techniques to Produce Improved Machine Learning Results.” Toptal Engineering Blog, Toptal, 4 Feb. 2016, www.toptal.com/machine-learning/ensemble-methods-machine-learning.
- Bhande, Anup. “What Is Underfitting and Overfitting in Machine Learning and How to Deal with It.” Medium, GreyAtom, 18 Mar. 2018, medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-learning-and-how-to-deal-with-it-6803a989c76.
